Bindings in Rust: Much More Than Just Variables
The French version of this page is available here
Table of Contents
- TL;DR
- Introduction
- Binding mutability
- Binding mutability test
- A first detour to understand what happens in memory
- A second detour to understand parameter passing, the heap and the stack
- End of the second detour. Back to the question concerning the mutability of data in memory.
- End of the first detour. Back to the question concerning the mutability of the binding
- End of analysis of the 1st line of code
- Second line of code
- Study of the fill_vec() function
- The solution with associated comments
- Mutability of references
- Variations on mutability
- The lifetime property of bindings
- Conclusion
TL;DR
In a Rust context, I think it’s better to stop talking about variables and instead talk about bindings. Indeed, a binding is richer than a classic variable.
- It associates a name with the state of an instance of a type
<T> - It adds properties
- of mutability
- of ownership
- of borrowing
- of lifetime
- Static code analysis ensures that the properties of the bindings are respected.
To keep in mind:
blah_blah_blahis a mutable/immutable binding that binds the name to the state of a concrete instance of a type<T>.- Ownership rule : Each concrete instance has a single owner at any given time and is automatically dropped when that owner goes out of scope.
- Reference rule : At any given time you can have either one mutable reference (writer) or multiple immutable references (readers). Compilers make sure the good things happen — the logical errors are on you.
Introduction
Like many people new to Rust, I installed Rustlings. Here is the code for the exercise move_semantics3.rs.
// TODO: Fix the compiler error in the function without adding any new line.
fn fill_vec(vec: Vec<i32>) -> Vec<i32> {
vec.push(88);
vec
}
fn main() {
// You can optionally experiment here.
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn move_semantics3() {
let vec0 = vec![22, 44, 66];
let vec1 = fill_vec(vec0);
assert_eq!(vec1, [22, 44, 66, 88]);
}
}
Don’t waste any time. Copy and paste the code above into the excellent Rust Playground page and press Test. You should see a message that looks like this:
Compiling playground v0.0.1 (/playground)
error: expected type, found keyword `mut`
--> src/main.rs:1:18
|
1 | fn fill_vec(vec: mut Vec<i32>) -> Vec<i32> {
| ^^^ expected type
error[E0423]: expected value, found macro `vec`
--> src/main.rs:2:5
|
2 | vec.push(88);
| ^^^ not a value
error[E0423]: expected value, found macro `vec`
--> src/main.rs:3:5
|
3 | vec
| ^^^ not a value
For more information about this error, try `rustc --explain E0423`.
error: could not compile `playground` (bin "playground") due to 3 previous errors
In short, it doesn’t pass the compilation and the goal of the exercise is precisely to correct the code in order to satisfy the compiler.
Note
When I say that “it doesn’t compile” it’s a misnomer. In fact, when we “compile” here are the main steps and the different tools used. In what follows, I will continue to say “it doesn’t compile” but now we agree on what that implies. I have put in bold 2 of the steps that we will have the opportunity to discuss again.
| Stage | Quick description |
|---|---|
| Parsing / Lexing | The source code is tokenized then organized |
| AST Construction | Construction of an Abstract Syntax Tree (AST) |
| Name Resolution | Resolving paths ( foo::bar), variables, modules |
| Type Checking | Each expression, function, variable is strictly typed |
| Trait Resolution | Traits constraints are checked |
| Lifetime Analysis | Analysis of lifetimes ( 't, etc.) for references |
| Borrow Checking | Ensures that there are no mutability or aliasing conflicts |
| Const Evaluation | const are calculated for validation |
| MIR Construction | Rust transforms the code into an intermediate representation optimized for analysis (the MIR) |
| MIR Optimizations | Rust optimizes the MIR before passing it to LLVM (low level virtual machine, see clang for example) |
| Code Generation (LLVM IR) | Rust generates LLVM intermediate code |
| LLVM Optimizations | LLVM optimizes even more |
| Machine Code | The binary code is produced |
OK… Let’s go back to the code. In the section test we create a vector vec0 that we pass as an argument to a function fill_vec(). The latter returns a vector vec1 that is none other than the previous one to which we have added the value 88 (see the line assert).
On its side, the function fill_vec() has a parameter vec which is a vector of i32 and it returns a vector of i32. In the body of the function there is a .push(88) which modifies the contents of the vector.
Here is the solution I proposed:
// TODO: Fix the compiler error in the function without adding any new line.
fn fill_vec(mut vec: Vec<i32>) -> Vec<i32> {
// ^^^----- Do you see the `mut` here?
vec.push(88);
vec
}
fn main() {
// You can optionally experiment here.
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn move_semantics3() {
let vec0 = vec![22, 44, 66];
let vec1 = fill_vec(vec0);
assert_eq!(vec1, [22, 44, 66, 88]);
}
}
In the function signature fill_vec() I added a mut in front of the parameter vec.
Okay, great… So? Well… Now we’re going to have to explain what’s going on and that’s going to allow us to revisit a lot of topics.
Binding mutability
We are interested in the first line of code
let vec0 = vec![22, 44, 66];
Here vec0 is a immutable binding that binds the name vec0 to the full state of a concrete instance of type Vec<i32>
Hey, hey, hey. Can you start again? You’ve lost me… I see what a vector of i32 is. It’s an array whose size can vary and which contains 32-bit integers. On the other hand, binding… Why don’t you just say that we declare a variable vec0?
In fact, if we were in another programming language, C++ for example, yes, we would say that the line corresponds to the declaration of the variable vec0. After that, I would explain that, basically, we associate with the name vec0 (which we will manipulate in the program) a memory area that contains values.
In Rust the notion of binding goes further:
- There is always the association of a name with a value. We will see later that it is rather the association of a name with the state of an instance but that is not important for the moment.
- That we enrich with additional properties. Examples: Who owns it? Can it be changed? Can it be loaned? For how long?…
- These properties are used at compile time (not at runtime) to prove that the code is managing memory correctly (reading, writing, freeing, concurrent accesses, etc.)
A binding is therefore a strong commitment (a contract). We sign it with our blood to the compiler, and the latter will refuse to compile our code if we don’t keep our word. As you can see, the atmosphere in Rust is quite nice, but hey, it’s for our own good.
That being said, I propose that from now on we start using the word binding instead of the word variable.
Now, you have to know this, but in Rust, by default, everything is immutable . Where, for example, in C++, everything is mutable by default.
// code C++
int x = 42; // non const by default
const int y = 42; // a constant
In Rust, it’s the opposite:
let mut x = 42; // mutable binding
let y = 42; // immutable binding by default
const MAX_SCORE: u32 = 42; // a constant
// to show constants exist in Rust
Why Rust Says “Immutable” Instead of “Constant”?
In Rust, variables are immutable by default, and the opposite of mutable is immutable—not constant. That’s intentional.
letcreates a binding, which links a name to a value. By default, this binding is immutable.Using
mutallows to change the value that the binding refers to.This is different from declaring a constant, which uses the
constkeyword.A
constin Rust is:
- Evaluated at compile time
- Inlined wherever it’s used
- Never mutable, not even with
mut- Not tied to a memory location like a binding
So even though both immutable bindings and constants can’t be modified, they are different concepts:
immutablerefers to whether a binding can be reassigned or notconstdefines a compile-time constant value that is embedded in the binaryThat’s why Rust talks about immutability instead of const-ness when dealing with variables. They may seem similar, but they serve very different purposes.
Ok, let’s go back on track. Regarding the previous code, it’s not better or worse in C++, it’s just a different philosophy. In C++ I have to specify if I want a variable to be constant. In Rust I have to specify if I want a binding to be mutable. From a security/safety point of view there is undoubtedly an advantage to everything being constant by default. It’s true that if we can avoid breaking a rocket at takeoff by writing a 1 where it shouldn’t, it’s not so bad. For the rest, I’m certain that if tomorrow we could rewrite the ISO specifications of C++ it’s the choice we would make (C dates from 72 and C++ from 85 while Rust only dates from 2006).
Now that we’ve talked about binding and immutability by default, if I go back to the first line of code:
let vec0 = vec![22, 44, 66];
vec0 is indeed a immutable binding on a Vec<i32>.
Um… Wait… Is it the binding that’s immutable? Isn’t it the contents of the vector? Are you sure about that?
Binding mutability test
Use the Rust Playground. Run tests, crash everything, read compiler messages, and “waste time” trying to figure out what’s going on. No one can do it for you, and it’s much better than watching kitten shorts on YouTube.
OK… “You talkin to me?”. You take it that way? Come on, get out if you’re a man. We’re going to go do a test outside. Copy and paste the code below into Rust Playground and press Run (CTRL+ENTER). It’s the same code as before except I put everything in the function main() and, to make you happy, I also added a mut in front of Vec<i32> in the function signature fill_vec().
fn fill_vec(vec: mut Vec<i32>) -> Vec<i32> {
vec.push(88);
vec
}
fn main() {
let vec0 = vec![22, 44, 66];
let vec1 = fill_vec(vec0);
assert_eq!(vec1, [22, 44, 66, 88]);
}
If you try to run the code, this is the message from the compiler:
Compiling playground v0.0.1 (/playground)
error: expected type, found keyword `mut`
--> src/main.rs:1:18
|
1 | fn fill_vec(vec: mut Vec<i32>) -> Vec<i32> {
| ^^^ expected type
error[E0423]: expected value, found macro `vec`
--> src/main.rs:2:5
|
2 | vec.push(88);
| ^^^ not a value
error[E0423]: expected value, found macro `vec`
--> src/main.rs:3:5
|
3 | vec
| ^^^ not a value
For more information about this error, try `rustc --explain E0423`.
error: could not compile `playground` (bin "playground") due to 3 previous errors
Basically… It says that on the first line of the code there is a syntax error. Indeed, after the colon that follow the parameter name vec, it expects a type and it read mut. Now, if you modify the code as below (in the signature of fill_vec(), mut is in front of the binding name vec) everything should go well.
fn fill_vec(mut vec: Vec<i32>) -> Vec<i32> {
vec.push(88);
vec
}
fn main() {
let vec0 = vec![22, 44, 66];
let vec1 = fill_vec(vec0);
assert_eq!(vec1, [22, 44, 66, 88]);
}
I’m still stuck on the first line of code. So I don’t want to talk about function calls etc. for the moment. But hey, the little test we just did confirms what I was saying. Mutability is a property of the binding, it’s not a property of the data ([22, 44, 66]) and even less of the name (vec0).
Ok… Mutability is associated with binding… But then the data is modifiable? I don’t understand anything!
A first detour to understand what happens in memory
Don’t move. We’re going to have to take a detour to understand what’s happening in memory. This should allow us to realize that in the latter, physically, all areas are potentially mutable. What saves us is that in the code we announce what we want (mutable, immutable) and then the compiler, aka Vinz Clortho, Gozer’s Key Master, keeps an eye on things and authorizes (or not) that this or that memory area be modified.
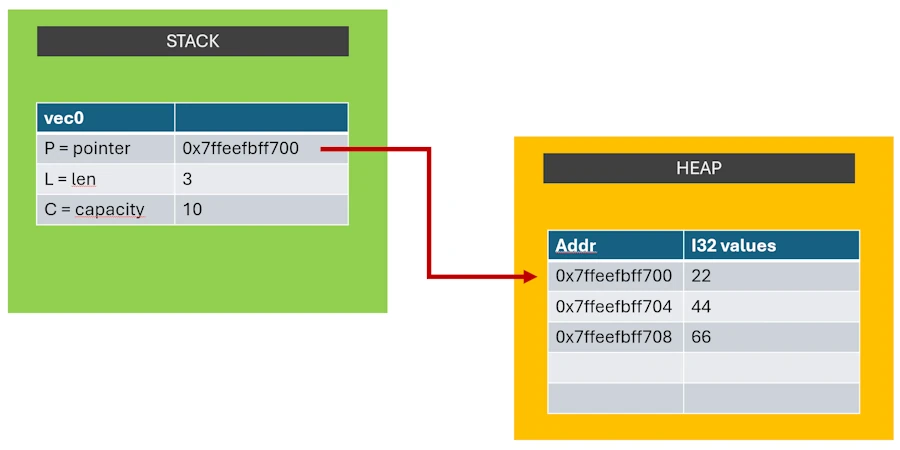
Come on, let’s go, I’ll explain it to you and it’s a good thing because the data type Vec<T>(vector containing data of type T: i32, f64…) is interesting. Indeed, even if in the code we manipulate it as a single entity, it is made up of 2 parts:
- On one side, there is a control structure. I call it PLC. It’s not the official term. I think I read “structure Vec
", "internal representation" or "metadata". - and on the other the data set (
[22, 44, 66]in our example). There, I believe that the official term is simply “buffer”.
The PLC control structure contains 3 fields:
- P : the address where the data (
[22, 44, 66]) is stored in memory. It is a pointer. - L : the current length of the vector (3 in our example)
- C : the capacity of the vector (10 for example). If this were the case, the vector would contain 3 elements of type
i32and it would have the possibility of receiving 7 more before having to be resized.
The dataset:
- It is a memory area that contains the 3 32-bit integers:
[22, 44, 66]
Additionally, the 2 components of the data type Vec<T> are stored in 2 different memory areas:
- The control structure (PLC) is on the stack
- The dataset is on the heap
If you want, you can imagine that in memory the situation looks like this:
A second detour to understand parameter passing, the heap and the stack
But why is it so complicated? Sorry, but we’re going to have to take an extra detour to understand why a vector is separated into two parts. Indeed, we need to understand the basic principle of passing parameters from one function to another, and then introduce the two memory areas, heap and stack. Once that’s done, we’ll be able to truly understand why mutability is the mutability of the binding and not the data.
Here we go again. Imagine… Imagine that we are in a function main(). We want to call another function and pass it a parameter. Let’s keep it simple to start. Let’s imagine that we want to pass an integer value 1 . In order to properly decompose the events, we will use the PC that we saw in The 3-Body Problem.

So? How do we do it? I suggest we put the value in a workbook, give this workbook to a rider, and send the rider to the other end of the plain. There, we open the workbook, retrieve the value, and execute the function code, taking into account the received value. When it’s finished, the rider returns. The workbook is empty because the function didn’t return anything. We then resume executing the function main().
Cool, that works. Now if we want to pass 2 integers. Same principle. However, be careful with the order. I have to agree with the function to say that the first sheet of the workbook corresponds to the first parameter and the second to the second parameter. For example, in the C++ specifications nothing forces the compiler to respect a particular order (MSVC goes from right to left, clang from left to right), in Forth and assembler the parameters are passed from right to left…
Cool, it still works. And now if I want to pass a real number (3.14159) and an integer (42). Same here, I pay attention to the order and write 3.14159 on one page and 42 on the other.
Cool, it continue to work. Now let’s imagine that I want to pass an array of pixels (an image) whose size is known at compile time (640x480 pixels all coded on one byte each). Here, it’s longer but I’m going to use 640x480 pages and put on each one a value between 0 and 255. At the end the function will read all the pages of the workbook and be able to reconstruct the image locally.
Well, that’s it, we’re done! Yeah… Almost… What happens now if I want to pass an array of numbers whose length I don’t know at compile time? Also think about cases where I want to pass an array whose length is likely to vary during program execution. This is called a vector .

We’re dead… It’s not possible… Indeed, you’re right, when the rider arrives, the function won’t know how many pages it has to pop (read) from the binder. That said, we can get out of it if we apply the principle of indirection (“All problems in computer science can be solved by another level of indirection.” [David Wheeler]).
Basically, instead of passing the vector itself, we will pass the description of the latter. It has a fixed size. For example, we can decide to describe a vector with 2 pages in the workbook. One page contains an integer that indicates the number of values in the vector and another page indicates with another integer, the place in the field, where to fetch the values when we need them. Everything happens as if we were passing a vector of variable size to the function, but this comes at the cost of slower provision. Indeed, instead of reading the values of the vector directly from the pages of the workbook, we will have to make a rider go back and forth to the other end of the field to retrieve the values we will need.
We can remember that:
- the stack
- allows you to store local variables
- when a function calls another function passing it parameters
- it puts the latter on the stack (push)
- the function retrieves them in the correct order (pop)
- we only put parameters of known size and simple types (trivially copyable) in the stack: int, bool, float, fixed array, tuple & struct with simple types, memory addresses
- the heap is a free area of the field where you can drop things
- these things (data structures) can have dynamic sizes
- everyone (all functions) who knows where a thing is (it know its address) can access it in reading or writing
So we understand why the vector is composed of 2 pieces:
The control structure: It has a fixed size, known at compile time. It can be passed onto the stack to “pass” the vector to a function.
- If the vector
vec0is mutable, the parameterlenmay change from 3 to 18 but this value will always be coded by oneusize(think of a 64-bit integer). - Likewise, if for some reason we have to move the area containing the data (we go from 3 to 300 data for example and we run out of space), the address (the value of the pointer I mentioned previously) will change but it will always be a 64-bit address.
- So, even if the values of the fields in the control structure change, its size, the number of bytes it occupies, will always be the same.
- It is this fixed-size structure that we will pass from one function to another via the stack.
The dataset:
- It is likely to see its size evolve.
- So we store it on the heap.
Ok, ok… I understand why a dynamic data type like a vector is split into 2 parts (descriptive on the stack and data on the heap) but where are the stack and the heap?
In the context of a process (an executable) running under Windows, this is (roughly) what the memory map looks like (it’s similar under Linux. Under Mac, I don’t know).
+-------------------------+ ← High addresses (ex: 0xFFFFFFFFFFFFFF)
| Kernel Space | ← System reserved (not accessible)
+-------------------------+
| Stack (grows ↓) | ← Local variables, function returns
| | Dynamically allocated at runtime
+-------------------------+
| Guard page / padding | ← Stack overflow protection
+-------------------------+
| Heap | ← new / malloc : dynamically allocated
| (grows upwards ↑) |
+-------------------------+
| BSS Segment (.bss) | ← Global variables NOT initialized
+-------------------------+
| Data Segment (.data) | ← Global variables initialized
+-------------------------+
| Code Segment (.text) | ← Executable code, functions
+-------------------------+
| PE Headers (.exe) | ← PE file headers (Portable Executable)
+-------------------------+
| NULL Page (invalid) | ← Causes segfault in case of dereferencing
+-------------------------+ ← Address 0x0000000000000000
And if I simplify further, here is what we need to remember:
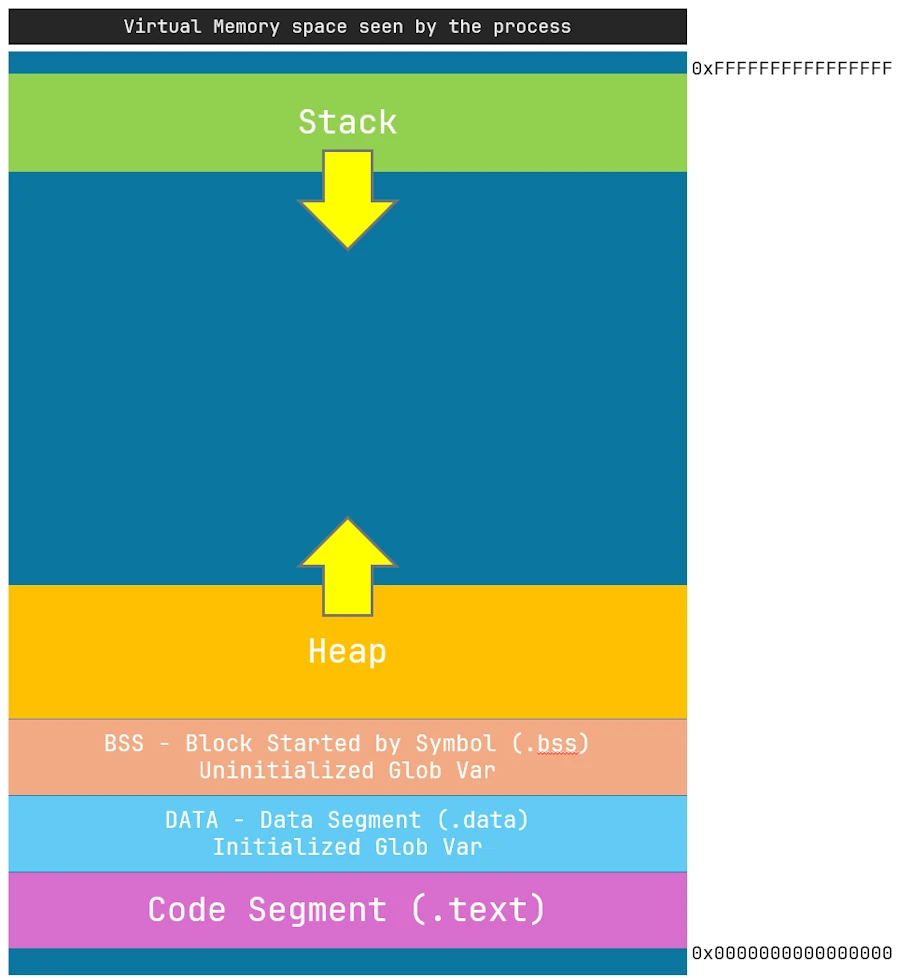
- The executable program (the process) believes that it is alone
- This idiot thinks he has access to a 64-bit memory space with addresses from 0x00.. to 0xFF.. In fact, it’s the OS that makes him believe that, but no, of course, he’s in a virtualized memory space.
- The code that is executed is located in the “Code Segment” section.
- Then there are 2 areas which contain the initialized and uninitialized global variables respectively.
- The size of the memory block
[.text + .data + .bss]is fixed and known at the end of compilation and linking. So that’s good, it will not change.
When the program starts, the processor executes the instructions that are in the segment .text. If it needs the value of a particular global variable, it looks for it in the area .data.
Then, if the program needs to create a local variable it will do so in the stack and if it needs to allocate a memory area it will do so in the heap.
To give you an idea, on Windows, the main process’s stack size is 1MB (4KB are pre-allocated to save time). This is configurable if needed. Then each created thread has its own stack whose default size is 2MB (this is also configurable).
Regarding the heap, we will say that initially its size is 0.
And what happens if the downward-growing stack meets the upward-growing heap? That’s a cross of streams, and everyone knows you should never cross the streams. That would be bad.
What you need to remember at the end of this second detour:
- Parameters passing is done via the stack
- Data whose size is fixed and known at the end of compilation is placed there
- The heap and the stack are two similar memory areas.
- They are both read-write and grow towards each other.
- Since
Vec<T>it is variable length, it cannot pass through the stack - We therefore decided to break it down into 2 parts
- A PLC structure, of fixed size and which can be passed through the stack
- The values that are on the heap
And there you have it. You understand why Vec<T> it’s so “complicated”. It’s just because we wanted to be able to pass it as an argument to a function.
End of the second detour. Back to the question concerning the mutability of data in memory.
As we have seen, the heap and the stack are in the virtual memory space that the program perceives. “Physically” these two areas are mutable. For example, we don’t have the means to store immutable data in read-only memory.
So to answer the question: yes, potentially the data (whether on the heap or in the stack) is all mutable.
What guarantees that the correct read and write operations are performed on the data (whether in the stack or the heap) at runtime is the static analysis of the code that is done during compilation. The compiler does not treat this or that memory location (stack or heap) differently. It monitors the bindings and their properties. From its point of view, there is no difference in treatment between the stack and the heap. What matters is that the bindings’ properties are met.
It’s like in C++. If I declare a variable const, whether it’s on the heap or in the stack, if I modify it I get hit on the fingers with a ruler (and the ruler is made of metal, not rotten plastic).
At our level, we can imagine that during compilation, there is a table which takes inventory of all the bindings, of all the memory zones and that if at some point, a piece of code tries to modify a immutable binding, the compiler screams.
The thing is, this heavy, long, and tedious analysis only takes place during compilation. The goal is that at the end of the latter, we know for sure that at the time of execution everything will go well and that we will not try to modify a immutable binding for example.
Finally, when everything is proven, when the code is compiled, we go for it. At runtime there are no more tables or anything else. Everything happens as if the day before the MotoGP tests you take your bike and go for a lap of the track. You go slowly, you note everything. The little bump here, the dip there, right at the apex, the spot to use as a braking point… You go slowly and if necessary you retrace your steps. When it’s clear, when everything is checked, the next day you don’t ask yourself any more questions… Full throttle!

One last note before moving on. For now, we’ve only seen the “mutability” property of the binding, but nothing prevents us from adding others. For example, lifetime properties. We’ll talk about this later. And this, unless I’m mistaken, is not tracked by a C++ compiler.
What to remember at the end of the first detour:
- From the compiler’s point of view, the stack and the heap are memory areas where one can read or write
- The data is therefore potentially always mutable.
End of the first detour. Back to the question concerning the mutability of the binding
Okay… And about the mutability of the binding. Don’t try to pull the wool over my eyes. You still haven’t answered my question!
In fact, considering the code test we did and the 2 (long) detours we took, it is clear that:
- Data, whether on the heap or in the stack, it doesn’t matter, is always modifiable.
- The compiler knows the mutability properties of different bindings
- During static analysis the compiler detects if the code tries to do something forbidden (modify a immutable binding for example)
- What is allowed or forbidden is what is written as property in the binding
So yes, I confirm mutability is a property of binding
End of analysis of the 1st line of code
We’re still on the first line of code (at this rate we’re not out of the woods yet…)
let vec0 = vec![22, 44, 66];
On the other hand, big progress… From now on we understand the sentence: vec0 is a immutable binding which links the name vec0 to the complete state of a concrete instance of Vec<i32>.
Um… Sorry… I understand 80% of the sentence but I don’t understand why you’re talking about “the complete state of a concrete instance”. In fact, it took me a long time to get to this sentence. Let me explain, and for that, we start from the line of code:
let vec0 = vec![22, 44, 66];
What you’ll read here and there is usually stuff like “a binding links a name to a value”.
In the specific case of the line of code you might read things like: “vec0 is a immutable binding that binds the name vec0 to the value Vec<i32>”
OK… Great, but what is the value? The PLC part of the vector? The values in the table? Actually, it’s all of these things at once. Since I had a lot of trouble with the word “value” in the case of a vector, my first idea was to tell myself that the “value” of a vector (or any other non-trivial data structure) is the hash code of the instance.
Typically I can construct and display the hash code of an instance Vec<T> with the code below:
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
fn main() {
let vec0 = vec![22, 44, 66];
// Create a new hasher
let mut hasher = DefaultHasher::new();
// Feed the vector into the hasher
vec0.hash(&mut hasher);
// Finalize the hash and get the result as a u64
let hash_code = hasher.finish();
// Print the hash code
println!("{}", hash_code); //2786706741450235691
}
It was becoming clearer to me and I could say to myself: vec0 is a immutable binding that links the name vec0 to the hash code of the vector instance. And there “Bingo, here is DNA dyno…”. No, not quite but “Bingo, now I understand that if I modify one of the PLC values or one of the table values I will take one because that will modify the hash code value.”
But if you think about it, the hash code captures and synthesizes, in a single value, the state at a given time t of the instance I have in my hands. In other words, if I now talk about state rather than hash code, it amounts to the same thing.
The description of the first line of code evolves and becomes:
vec0is a immutable binding that binds the namevec0to the state of a Vec. vec0is a immutable binding that binds the namevec0to the full state of a Vec. This is to say that in a vector it concerns the data and the control structure. vec0is a immutable binding that binds the namevec0to the full state of an instance ofVec<i32>. Yes because in the code I manipulate instances rather than types.vec0is an immutable binding that binds the namevec0to the full state of a concrete instance of a typeVec<i32>. Probably too much. It’s just to emphasize that the instance in question is something likeVecorStringand not really an abstract type (Trait).
Finally, what I keep in mind is: blah blah blah is a (im)mutable binding that binds the name blah blah blah to the state of a concrete instance of a type <T>.
That being explained, let’s go back and about the first line of code
let vec0 = vec![22, 44, 66];
We can say that vec0 is an immutable binding that binds the name vec0 to the complete state of a concrete instance of a type Vec<i32>.
vec0this is the name of the binding (introduced bylet)- The vector consists of a PLC structure that is on the stack
- Its pointer (P) points to the data
[22, 44, 66]that is on the heap - The binding
vec0is not mutable. - If I touch anything that modifies the state (think of the hash code if necessary) of the vector (PLC or values) I get a slap in the face.
At this point, regarding the binding, you must keep in mind
- It associates a name with the state of an instance of a type
- It adds properties
- of mutability
- …
- Static code analysis ensures that the properties of the bindings are respected.
Alright, it’s time to move on to the second line of code.
Second line of code
Here is the line that interests us:
let vec1 = fill_vec(vec0);
And I put it face to face with the function fill_vec()
fn fill_vec(vec: Vec<i32>) -> Vec<i32> {...}
Now, in order to move forward, I’ll give you THE ownership rule of Rust:
Ownership Rule
Each value has a single owner at any given time and is automatically dropped when that owner goes out of scope.
Print it and post it in your bathroom…

Given what has been said about states and concrete instances, I keep in mind:
Each concrete instance has a single owner at any given time and is automatically dropped when that owner goes out of scope.
Regarding which one to display in your toilets, I’ll let you manage that.
We’re not going to spend 3 hours on it, but hey, some words are important.
1. Each value has a single owner at any given time : This means that during compilation, static code analysis will track which binding owns which concrete instance and call timeout if we try to have two bindings on the same instance. Be careful, we are talking about the owner. I have a Ferrari. Even if I lend it to you, I remain the owner. On the other hand, if I give it to you… “To give is to give, to take away is to steal.” You become the new owner and I no longer have any rights to it.
Be careful… So there’s a subtlety in the previous code and you’ll see that it’s much better when you read it. Indeed, during the call, fill_vec(vec0) what happens? Do we do a pass by value? A pass by reference? Do we give or lend the binding vec0 to the function? Yes, you’re right, it “looks” very much like a pass by value. Everything happens as if we were writing:
vec = vec0
In other words, we will give the binding vec0 to the function fill_vec().
2. and is automatically dropped when that owner goes out of scope : A scope is just an area of code between 2 braces { and }.
Let’s illustrate this using the entire function code move_semantics3() found in section #[test].
fn move_semantics3() {
let vec0 = vec![22, 44, 66];
let vec1 = fill_vec(vec0);
assert_eq!(vec1, [22, 44, 66, 88]);
}
No worries. Keep in mind that we just said that the binding vec0 was given when calling to fill_vec(). For now, we don’t have the necessary knowledge yet, so I can’t say much about it.
On the other hand, when the fill_vec() returns, what is certain is that the binding vec1 is the owner of a state. There, what I can say is that on the last line, where there is the closing brace, the binding vec1 goes out of scope. And there, automatically, it’s not even up to me to do it, the concrete instance to which vec1 was bound will be deleted from memory.
To be clear, the concrete instance that will be dropped (removed from memory) is the one Vec<i32> that contains the values [22, 44, 66, 88].
So what will happen on the second line?
- the binding
vec0is passed by value to the functionfill_vec()( this is false but we’ll come back to it in 2 min.) - the binding
vec0ceases to be proprietary - the binding
vecfrom thefill_vec()function becomes proprietary - the binding
vec0is invalidated. It remains accessible but we get a compilation error if we try to use it - When the
fill_vec()function returns, the immutable bindingvec1binds the namevec1to the state of a type’s instanceVec<i32>. vec1is the owner of the instance in question
At this point, regarding the binding, you must keep in mind
- It associates a name with the state of an instance of a type
- It adds properties
- of mutability
- of ownership
- …
- Static code analysis ensures that the properties of the bindings are respected.
Study of the fill_vec() function
fn fill_vec(vec: Vec<i32>) -> Vec<i32> {
vec.push(88);
vec
}
- The function signature indicates that it has as a parameter a binding
vecwhich is linked to the state of an instance of a typeVec<i32> - The function returns a binding that is bound to the state of an instance of a type
Vec<i32>
The question we can ask ourselves is how, at the time of the function call, the ownership of the binding vec0 is passed to vec. Here, it’s fine because we only have 3 values involved, but if we had a vector of 1 GB of data, we would have a problem. No?
I’ll let you think about it… So?
Remember, Barbara, what circulates through the stack is not the data set itself. Here we have only that, [22, 44, 66] but in fact, thanks to the principle of indirection and the pointer of the control structure, the number of values in the vector does not matter. Only the control structure (PLC) which contains 3 simple type values will pass through the stack. To give you an idea, we can assimilate these 3 data to 3 64-bit integers. It’s super fast and, above all, it’s independent of the number of values in the vector.
On the other hand, you have to keep in mind that it’s not a copy of vec0 in vec but a move (hence the name of the exercise. Clever guys…).
Wait, wait… You can come back to your move story. You went a little too fast. No problem. If I make a copy of simple type variables (trivially copyable, int, float… but not a Vec<T>) the code below works as expected:
fn main() {
let mut my_int1 = 42;
let my_int2 = my_int1;
my_int1+=1;
let my_int3 = my_int1;
assert_eq!(my_int1, 43);
assert_eq!(my_int2, 42);
assert_eq!(my_int3, 43);
}
I copy my_int1 in my_int2 and look, after the copy, I can still increment my_int1 and copy its new value in my_int3. Normal behavior!
OK… Let’s try to do the same thing with a “not so simple” data type ( Vec<T>, String…) :
fn main() {
let my_string1 = String::from("Zoubida");
let mut my_string2 = my_string1; // my_string1 is no longer available
my_string2.push_str(" for ever");
let my_string3 = my_string2; // my_string2 is no longer available
//assert_eq!(my_string1, "Zoubida"); // would panic
//assert_eq!(my_string2, "Zoubida for ever"); // would panic
assert_eq!(my_string3, "Zoubida for ever");
}
As is, the code works, but if you unfortunately delete the comments of the assert line, the compiler jumps down your throat and you die in terrible pain, forgotten by everyone. For example, if I delete the first comment, this is what I read:
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `my_string1`
--> src/main.rs:7:5
|
2 | let my_string1 = String::from("Zoubida");
| ---------- move occurs because `my_string1` has type `String`, which does not implement the `Copy` trait
3 | let mut my_string2 = my_string1; // my_string1 is no longer available
| ---------- value moved here
...
7 | assert_eq!(my_string1, "Zoubida"); // would panic
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ value borrowed here after move
|
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let mut my_string2 = my_string1.clone(); // my_string1 is no longer available
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `playground` (bin "playground") due to 1 previous error
Read the compiler messages. No one else will do it for you, and the guys worked their asses off to find a way to help us, so let’s use what they have to offer…
In addition, it’s super clear. The compiler tells us that on line 3 there was a move from the binding my_string1 to the binding my_string2 because the binding my_string1 is linked to the state of an instance of type String and that this data type does not implement a function that would allow it to be copied (it does not implement the Copy trait). So, since we cannot make a copy (but only a move) we have no right to use the binding my_string1 in the assert to compare it to “Zoubida”.
Just to prove I’m trying to be honest… Of course it’s possible to make an explicit copy of a String. You have to use .clone(). The thing here is that since the Copy trait isn’t implemented, by default we make .move().
In fact, at the end of line 3, everything happens as if my_string1 was no longer usable (which it is) and my_string2 had replaced my_string1.
It may be worth remembering that:
| Operation | Syntax | Effect |
|---|---|---|
| Copy | x = y | x and y are usable |
| Move | x = y | x is usable, y is no longer usable |
With these “move” stories covered, I return to the function code
fn fill_vec(vec: Vec<i32>) -> Vec<i32> {
vec.push(88);
vec
}
It should be noted that when we arrive in the scope of the function fill_vec() the binding vec0 is no longer the owner. The new owner is vec.
Ah OK, that’s it, I get it. Then we push, we return, and it’s done. Yes, almost, but in the meantime we have a compilation error to deal with. Something like this:
error[E0596]: cannot borrow `vec` as mutable, as it is not declared as mutable
--> exercises\06_move_semantics\move_semantics3.rs:3:5
|
3 | vec.push(88);
| ^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | fn fill_vec(mut vec: Vec<i32>) -> Vec<i32> {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `exercises` (bin "move_semantics3") due to 1 previous error
Well, of course, no one reads it and everyone complains… Let’s make the effort to read anyway. So, what does it say?
The compiler clearly indicates what is causing the problem: ^^^ cannot borrow as mutable and it tells us that it is vec the one responsible. The icing on the cake is that it even gives us the solution. It says consider changing this to be mutable. And as if that wasn’t enough, it finally gives the solution fn fill_vec(mut vec: Vec<i32>) -> Vec<i32> { with little ones +++ like in a diff to tell us what to add. Isn’t that cute?
Seriously, we’re almost reaching Nirvana. Apart from the word borrow, he’s got it all right. Basically what he’s saying is that vec being a immutable binding, it doesn’t allow the method to be invoked .push() on it. In fact, the latter attempts to modify the state of the concrete instance by adding the value 88 to it.
So what do we do then? Read, I tell you… The compiler gave us the solution. We need to re-qualify the binding vec. Remember, by default everything is immutable. So in the signature:
fn fill_vec(vec: Vec<i32>) -> Vec<i32>
The parameter vec is immutable. We must therefore modify the signature as the compiler suggests:
fn fill_vec(mut vec: Vec<i32>) -> Vec<i32>
* Wait… There’s something I don’t understand… We had an immutable vector at the beginning. We pass it to a function. And hey presto, it can become mutable… That’s not very secure. Is it?*
Let’s go back to the time of the call. What exactly is happening… Remember the rule of ownership: Each value has a single owner at any given time and is automatically dropped when that owner goes out of scope. (Each concrete instance has a single owner at any given time and is automatically dropped when that owner goes out of scope.)
To comply with this rule, we explained that vec0 it was “moved” and no longer usable after the function call. So, don’t worry, vec0 since it’s no longer usable, no one can empty your bank account or steal your digital identity. The “secure” aspect is fine, it’s taken care of.
Next, and this is important to realize. It’s not the data or memory areas that are mutable or immutable. It’s the bindings (mutability is a property of the binding). Typically, the data allocated on the heap at the time of creation of vec0 was “physically” mutable. On the other hand, the compiler monitored the mutability of the binding vec0, it saw that we hadn’t done anything illegal and it worked. Then, we move the binding from vec0 to vec. OK, fine. But if I give you my Ferrari. Nothing prevents you from adding a caravan hook or repainting it yellow. You are the new owner, you do what you want. In other words, it is not forbidden when transferring the binding from vec0 to vec to reclassify it as mutable. We will then have the right to modify the state of the concrete instance at the other end of the binding.
Again, these mutability stories are a property of the binding, not the binding data. However, it is a contract that we sign with the compiler and that we agree to respect. If I say that vec is immutable in the signature, I do not have the right to modify the state of the type instance Vec<i32> (and vice versa if I qualify the binding with mut). It is the compiler, and in particular Rust’s borrow checker, which is responsible for enforcing the law, and we are allowed to say that it is as accommodating as Judge Dredd.

The solution with associated comments
//`vec0` is a mutable binding that links the name ``vec0`` to the complete state of a concrete instance of type ``Vec<i32>``.
// On the heap, the data pointed to by ptr are not copied (and are mutable)
// The `mut` keyword allows the function to modify state of the local concrete instance of type Vec<i32>
// This is possible because fill_vec owns vec_in exclusively
// vec_in is a mutable binding to Vec<i32>, not a mutable Vec<i32> itself
// In the function signature, `mut` works just like it would in: let mut vec_in = ...
fn fill_vec(mut vec_in: Vec<i32>) -> Vec<i32> {
vec_in.push(88); // the state is modified because the data are modified
vec_in // vec_in is moved to the caller
}
// fn main() {
// vec0 is a immutable binding
// A binding associates a name to a value + rules of ownership & borrowing
// mutability is a property of the binding NOT a property of the value (nor the name)
// The term binding in Rust represents a strong contract with the compiler, not just a “classic" variable.
// Here, this means you cannot call vec0.push(...) or reassign vec0
// However, the Vec internally holds a pointer to heap-allocated memory, which is mutable by nature
// Rust allows the ownership of vec0 to be transferred (moved), even if the binding is not mutable
let vec0 = vec![22, 44, 66]; // immutable binding: cannot change vec0 or call vec0.push(...)
// but the heap memory behind it is mutable
// On the heap, data pointed by ptr are mutable
let vec1 = fill_vec(vec0); // vec0 is moved into fill_vec
// vec0 is no longer usable after this point
assert_eq!(vec1, [22, 44, 66, 88]);
// }
Mutability of references
If you haven’t already, I highly recommend reading this book.

I’ll spare you the details, but in one of the bonus features in Chapter 1, which deals with “Two Pointers,” there’s an exercise where we’re asked to group all the zeros we could find at the end of a vector. You can take a look at this puzzle here in Rust or here in Python.
Below is a solution in Rust
- In the function
main()we create a bindingvec0that binds the namevec0to the state of a concrete instance of typeVec<i32>. - You notice that when it is created, we give the binding (
let mut vec0) the propertymut. We can therefore modify the state of the vector. - In a very original way, there is then a function named
shift_zeros_to_the_end()to which we pass as an argument something based onvec0(we will come back to this in 2 minutes) - Unlike before, the function does not return anything.
- On the other hand, “Abracadabra!”, on the last line
assertallows us to check that the 0s have been pushed to the bottom of the bindingvec0
fn main(){
let mut vec0 = vec![1, 0, 5, 0, 3, 12];
shift_zeros_to_the_end(&mut vec0);
assert_eq!(vec0, [1, 5, 3, 12, 0, 0]);
}
fn shift_zeros_to_the_end(nums_in: &mut Vec<i32>){
let mut left = 0;
for right in 0..nums_in.len(){
if nums_in[right] != 0 {
nums_in.swap(left, right);
left += 1;
}
}
}
- The function signature
shift_zeros_to_the_end()indicates that it expects as a parameter a named bindingnums_inwhich is linked to, I don’t really know what, based onVec<i32> - The code has no importance here
- Just note that once in the body of the function, we use it
nums_inas a mutable vector (we can exchange the contents of 2 cells for example) - In the end, everything happens as if the function returned nothing
Given everything we have already explained, we will allow ourselves to speed up a little and focus our attention on just two lines.
shift_zeros_to_the_end(&mut vec0);fn shift_zeros_to_the_end(nums_in: &mut Vec<i32>)
About shift_zeros_to_the_end(&mut vec0);
As a reminder, in the first code, main() we had a line like
let vec1 = fill_vec(vec0);
Here we have a line like this
shift_zeros_to_the_end(&mut vec0);
It’s not better or worse. The thing is, when the function returns, we don’t have a new binding. We continue to use the original binding ( vec0). However, we must give the function shift_zeros_to_the_end() the means to be able to modify the state of the concrete instance of the type. In other words, I lent you my Ferrari and I give you permission to clean it.
The idea is that this way of expressing things may well reflect our intention (“Here are the keys. Don’t forget to vacuum the Ferrari before you give it back.”) but hey, it’s a bit difficult in terms of writing (there’s even a little Klingon side to it…).

In fact, here, we don’t want to give up ownership of the binding, we just want to lend it temporarily (while the function shift_zeros_to_the_end() modifies the state of the concrete instance). In Rust, this is done by passing as an argument, not the binding (if we pass it, it is moved and we lose it) but a reference to the binding.
If I take the ALU (arithmetic logic unit) from the Three-Body Problem from earlier, I use a single sheet in the workbook where I write an integer (the coordinates) that will allow the recipient to find my binding in the field. By doing this, he knows where to find it and he can work on it. When he has finished, the rider returns to empty (no value returned). This is the signal for me that I can continue my work but using the modified version of my original binding. Everything therefore goes well as if I had lent the binding.
From a syntax point of view, to pass a reference to a binding rather than a binding itself, we use the notation &my_binding.
Well then why do I see it written in the code &mut vec0? You’re a big boy… I’ll let you think about it… Done? No? Still not? Okay, what happens if in the function main() we write a line like:
shift_zeros_to_the_end(&vec0);
What is the philosophy, the mindset of Rust (compared to C++ for example)? A bit like what we do… We talked about it at the beginning. Yes, very well…
By default, everything is immutable. And so if we write the previous line of code, we tell the compiler that we want to lend the Ferrari but we prohibit any modification. And of course, it will not pass the compilation because the compiler will detect that the signature of the function shift_zeros_to_the_end(nums_in: &mut Vec<i32>) is not respected (there is one &mut that hangs around).
Furthermore, even without the recipient’s signature, Rust requires that I explicitly express the modification permissions I am giving. Since I want to lend the binding vec0 I will pass a reference and since I want to allow modification of what it refers to I must write shift_zeros_to_the_end(&mut vec0).
Isn’t that a bit dangerous?…What happens if we give multiple references that could modify the same binding… Well done, I’m proud of you. You’re starting to think like Rust’s borrow checker. I even think you can answer your question. What would be acceptable from your point of view? Yes, well done again, there’s a rule that says:
Reference Rule
At any given time you can have either one mutable reference (writer) or multiple immutable references (readers).
In plain English, this means that during the static analysis of code, we will follow the loans and that during the execution of the program, we will only be allowed to have a single reference capable of modifying the concrete instance to which it points, or else, to have several references capable of reading the content of the same concrete instance. Between practice, this means that we cannot have a writer and 2 readers. It is either a writer or 2 readers (cheese or dessert but not both).
Um… If I lend a &mut, why can I still use it vec0 afterward? It should have been “consumed” and no longer be available. Right? Well then… You’ll be able to show off at the next family meal… In fact, when you lend a binding vec0 as a &mut vec0, Rust performs what’s called an implicit reborrow :
- during the call to
shift_zeros_to_the_end(&mut vec0), exclusive access to the content is temporarily transferred to the function - when the function exits, the reborrow ends, and the binding
vec0becomes accessible and usable normally again inmain() - Unlike a move,
vec0it is not lost after the call. It simply regains its initial usage rights.
Notes: I confirm to you
- it is
&mutand notmut& - for a mutable reference you will see
my_function(&mut bob)with a space&mutis a compound operator in Rust&mutis a single “logical keyword”, which reads “mutable reference to”
- for a immutable reference you will see especially
my_function(&bob)without a space whereasshift_zeros_to_the_end(& vec0)is just as legal but not or very little used (I don’t know why, it must be historical)
About fn shift_zeros_to_the_end(nums_in: &mut Vec<i32>)
It’s going to be fast. Very fast. Because from now on, we are strong, very strong…
The function has a single parameter which is a immutable binding that binds the name nums_in to the state of a concrete instance of type &mut Vec<i32>. It is very important to see here that the binding is immutable but that the concrete instance to which the name num_in is bound is, itself, mutable.
What, what, what… I didn’t understand anything. In the first part we had
fn fill_vec(mut vec_in: Vec<i32>) -> Vec<i32>{...}
And we said in the comments: vec0 is a mutable binding that links the name vec0 to the complete state of a concrete instance of type Vec<i32>.
Here, there is no mut in front of nums_in so nums_in it is a immutable binding. Then the binding associates the name nums_in with what? To the state of a concrete instance of the type &mut Vec<i32>. In the case of a reference type (mutable or not) on a thing, a concrete instance is the reference itself. So, I repeat: nums_in is a immutable binding that connects the name nums_in to a concrete instance of type &mut Vec<i32>.
The binding is not mutable but the state of Vec<i32> is mutable through the reference.
The solution with associated comments
// the function use a immutable binding that links the name nums_in to the state of an instance of type ``&mut Vect<i32>``
// The binding nums_in is immutable, but it holds a mutable reference
// This means we can mutate the Vec it points to, but we cannot reassign nums_in itself
// nums_in cannot be reassigned to point to another Vec
// but the Vec it refers to can be mutated (e.g. via push, swap, etc.)
fn shift_zeros_to_the_end(nums_in: &mut Vec<i32>){
let mut left = 0;
for right in 0..nums_in.len(){
if nums_in[right] != 0 {
nums_in.swap(left, right);
left += 1;
}
}
}
fn main(){
let mut vec0 = vec![1, 0, 5, 0, 3, 12]; // vec0 is a mutable binding so it can be passed as &mut
shift_zeros_to_the_end(&mut vec0); // we pass a mutable reference to allow the function to mutate the Vec
assert_eq!(vec0, [1, 5, 3, 12, 0, 0]); // values have been rearranged in-place
}
Little million dollar question…

What if the function main() looks like this:
fn main(){
let vec0 = vec![1, 0, 5, 0, 3, 12];
shift_zeros_to_the_end(&mut vec0);
assert_eq!(vec0, [1, 5, 3, 12, 0, 0]);
}
Yes, well done… It doesn’t compile…
Yes, but why? Yes, well done again! We create a immutable binding vec0 that we then pass as a mutable reference to the function shift_zeros_to_the_end(). The compiler rightly points out to us that we shouldn’t take it for an fool, that it has seen our shenanigans and that consequently it stops the compilation. Not one to hold a grudge, it indicates a solution which consists of adding a mut in front of vec0.
At this point, regarding the binding, you must keep in mind
- It associates a name with the state of an instance of a type
- It adds properties
- of mutability
- of ownership
- of borrowing
- …
- Static code analysis ensures that the properties of the bindings are respected.
For the fun…
The code below shows 2 possible implementations.
Either you pass the binding by reference or you move it. They both do the job.
However, we can notice that in the version _byref we only push a pointer to the binding onto the stack (8 bytes on a 64-bit OS).
In the _bymove stack, the control structure, which includes a pointer, a length, and a capacity, is pushed onto the stack. All three are encoded with 8 bytes on a 64-bit OS. In the end, 24 bytes are pushed onto the stack.
If the function needs to be called many times per second, it is probably better to use the version _byref. But before going any further, you need to measure (do a bench).
Otherwise, personally I prefer the version _byref because I find that it is the one that best expresses my intention.
fn shift_zeros_to_the_end_byref(nums_in: &mut Vec<i32>){
let mut left = 0;
for right in 0..nums_in.len(){
if nums_in[right] != 0 {
nums_in.swap(left, right);
left += 1;
}
}
}
fn shift_zeros_to_the_end_bymove(mut nums_in: Vec<i32>) -> Vec<i32>{
let mut left = 0;
for right in 0..nums_in.len(){
if nums_in[right] != 0 {
nums_in.swap(left, right);
left += 1;
}
}
nums_in
}
fn main(){
let mut vec0 = vec![1, 0, 5, 0, 3, 12];
shift_zeros_to_the_end_byref(&mut vec0);
assert_eq!(vec0, [1, 5, 3, 12, 0, 0]);
let vec1 = vec![1, 0, 5, 0, 3, 12];
let vec2 = shift_zeros_to_the_end_bymove(vec1);
assert_eq!(vec2, [1, 5, 3, 12, 0, 0]);
}
Variations on mutability
We’ve seen signatures like (mut nums_in: Vec<i32>) -> Vec<i32> and (nums_in: &mut Vec<i32>). Would it make sense to write something like (mut nums_in: &Vec<i32>) or (mut str_in: &mut Vec<i32>), and what could that be used for?
Here, treat yourself. You have all the elements you need to analyze the situation. Always make sure to distinguish between the mutability of the binding and the mutability of the reference. Take your time; we’re in no rush.
// The binding str_in associates the name str_in with the state of a concrete instance of type reference to a String.
// str_in is a not mutable binding; it cannot be reassigned to an other &String.
// The reference to the String is also not mutable; the content of the String cannot be modified through this reference.
fn dont_change(str_in: &String){
println!("{}", str_in); // Reads and prints the string. Cannot modify
}
// The binding str_in associates the name str_in with the state of a concrete instance of type mutable reference to a String.
// str_in is a not table binding; it cannot be reassigned to another &mut String.
// The reference to the String is mutable. The content of the string can be modified using this reference
fn change(str_in: &mut String){
str_in.push_str(" power!"); // Appends text to the original String
}
// The binding str_in associates the name str_in with the state of a concrete instance of type reference to a string slice (&str)
// str_in is a mutable binding; it can be reassigned to another string slice (&str)
// we cannot modify the data pointed to by the slice
fn change_view(mut str_in: &str) {
str_in = &str_in[1..3]; // Rebinds str_in to a substring of the original
// This is NOT a let. This is an reassignment
println!("{:?}", str_in); // Prints the new slice
}
// The binding str_in associates the name str_in with the state of a concrete instance of type &mut String.
// str_in is a mutable binding; it can be reassigned to another mutable reference to a String.
// The reference itself is mutable: the content of the String can be modified through this reference.
// The binding other associates the name other with the state of a concrete instance of type &mut String.
// other is a not mutable binding; it cannot be reassigned to an other mutable reference to a String.
// The reference itself is mutable: the content of the String can be modified through this reference.
// We need to annotate the lifetime because we manipulate two mutable references.
fn change_and_reassign<'a>(mut str_in: &'a mut String, other: &'a mut String) {
// Modify the original String
str_in.push_str(" modified");
println!("After modification : {}", str_in);
// Reassign str_in to point to another mutable String
str_in = other;
str_in.push_str(" changed");
println!("After reassignment and second modification : {}", str_in);
}
fn main() {
// Create a mutable String binding
let mut my_str = String::from("Banana");
// Pass an immutable reference to a function that reads the string
dont_change(&my_str);
// Pass a mutable reference to allow the function to modify the String
change(&mut my_str);
println!("{}", my_str); // Print my_str once modified String
// Pass an immutable reference (as a slice) to a function that creates a view into the string
change_view(&my_str);
let mut my_str = String::from("hello");
let mut another_str = String::from("world");
// Pass two mutable references
change_and_reassign(&mut my_str, &mut another_str);
// After the function, let's print the original variables
println!("my_str : {}", my_str);
println!("another_str : {}", another_str);
}
I’ll let you read the comments for the first 3 functions. Normally, there shouldn’t be any problems.
However, in order to be exhaustive, I absolutely wanted to have an example with 2 mut in the function signature. One for the mutability of the binding and another for the mutability of the reference. It took a lot of fighting with the compiler and I had no other choice but to specify the lifetimes of the references.
Don’t start complaining. I suggest you read the next section where we will only talk about the “lifetime” property of the bindings and then come back here to get your teeth into the function change_and_reassign().
The lifetime property of bindings
We’ll start with a simple problem of comparing the length of strings. Below is an example of code that works.
fn longest(s1: String, s2: String) -> String {
if s1.len() > s2.len() { s1 } else { s2 }
}
fn main() {
let s1 = String::from("to infinity");
let result;
{
let s2 = String::from(", and beyond!");
result = longest(s1, s2);
println!("Longest: {}", result);
}
println!("Longest: {}", result);
}
There are no traps or complicated things that we haven’t seen.
s1is a immutable binding that binds the names1to the state of a concrete instance of type String.- We start by creating a immutable binding that links the name
resultto the state of a concrete instance of the type “I don’t know yet, we’ll see later” - We create an artificial scope with two curly braces. This will be especially useful in the last example. Here, it’s just so the codes in the examples are very similar.
s2is a immutable binding that binds the names2to the state of a concrete instance of type String.- We call a function
longestto which we pass the 2 bindings - The return binding of the function
longestis moved inresult(this is when the compiler deduces thatresultwill be a binding to the state of an instance of a String type) - We display
- We get out the artificial scope
- We display
Concerning the function, longest it receives 2 immutable bindings on String types (well, I’ll keep it short, you get the idea) and it returns a binding of type String.
- The thing to note is that in Rust the
ifare expressions, not statements. - In other words, one
ifreturns a value and that is precisely what is done in the single line of code - Also note that there is no
;at the end of the line because the value of theifexpression is the returned binding
Everything is fine and we can read:
Longest: , and beyond!
Longest: , and beyond!
Now, imagine that for some reason we are asked to rewrite the function longest() so that it takes as parameters bindings whose end of the link is a string slice ( &str for those in the know)
Here is an example of code that doesn’t seem too bad…I won’t comment, it’s almost a copy and paste of the previous code.
fn longest(s1: &str, s2: &str) -> &str {
if s1.len() > s2.len() { s1 } else { s2 }
}
fn main() {
let s1 = String::from("to infinity");
let result;
{
let s2 = String::from(", and beyond!");
result = longest(&s1, &s2);
println!("Longest: {}", result);
}
println!("Longest: {}", result);
}
There’s just one small detail, nothing at all… It doesn’t compile and this is the message displayed:
Compiling playground v0.0.1 (/playground)
error[E0106]: missing lifetime specifier
--> src/main.rs:1:35
|
1 | fn longest(s1: &str, s2: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `s1` or `s2`
help: consider introducing a named lifetime parameter
|
1 | fn longest<'a>(s1: &'a str, s2: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `playground` (bin "playground") due to 1 previous error
I’ll let you read… Done?
The compiler tells us that the function returns a reference, which is all very well, but hey, he’d like to be 100% sure that the reference that will be returned will be a reference to data that, at the time of return, will still be valid data. Since he can’t figure it out on his own, he asks us to annotate the function signature with the lifetimes of the bindings concerned.
He even gives us an example that is correct. In fact, the function returns either or depending on the case s1 or s2. So the returned binding and the parameters must have the same lifetimes.
Trust in me, just in me…🎹 Copy and paste the code below. It should work.
fn longest<'t>(s1: &'t str, s2: &'t str) -> &'t str {
if s1.len() > s2.len() { s1 } else { s2 }
}
fn main() {
let s1 = String::from("to infinity");
let result;
{
let s2 = String::from(", and beyond!");
result = longest(&s1, &s2); // OK s1 and s2 are still living
println!("Longest: {}", result);
} // <- s2 goes out of scope
// println!("Longest: {}", result); // NOK result is s2 dependant
}
Here’s what happens in the signature:
<'t>: this introduces a lifetime parametertthat will be used to link the lifetimes of parameters and return values togethers1 : &'t str: The first parameters1is a string slice that must live at least as long asts2 : &'t str: The second parameters2is a string slice that must live at least as long ast-> &'t str: The function returns a string slice that must live at least as long ast
At runtime, in the console, we see Longest: , and beyond!
Now to really understand this story about binding lifetimes, delete the comment on the last line. This stops compiling and we get the following message:
Compiling playground v0.0.1 (/playground)
error[E0597]: `s2` does not live long enough
--> src/main.rs:11:31
|
10 | let s2 = String::from(", and beyond!");
| -- binding `s2` declared here
11 | result = longest(&s1, &s2); // OK s1 and s2 are still living
| ^^^ borrowed value does not live long enough
12 | println!("Longest: {}", result);
13 | } // <- s2 goes out of scope
| - `s2` dropped here while still borrowed
14 |
15 | println!("Longest: {}", result); // NOK result is s2 dependant
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `playground` (bin "playground") due to 1 previous error
You’re starting to get used to it now. I’ll let you read…
The compiler is really smart (personally I am amazed).
- On line 10 it points to the declaration of
s2(checks but line 10 is in the artificial scope which starts at line 9 and stops at line 13) - It clearly notices that on line 11 we use the binding
s2 - Finally, it indicates just below the second brace of the artificial scope that it
s2no longer exists - So he points to line 15, takes out the aluminum ruler and slaps us on the wrist because he is now able to prove to us that we are not respecting the contract we signed with him.
- We had annotated the function signature with the lifetimes
- We promised, swore, spat that
s1,s2andresulthad the same lifetimet - And yet… And yet in the code, the compiler is able to prove that the binding
s2does not have the same lifetime as the bindingresult
At this point, regarding the binding, you must keep in mind
- It associates a name with the state of an instance of a type
- It adds properties
- of mutability
- of ownership
- of borrowing
- of lifetime
- Static code analysis ensures that the properties of the bindings are respected.
Conclusion
Honestly, I think you’ve had enough. I’m wondering if I should split this post into two or more parts. We’ll see…
For the rest, concerning the binding I hope to have convinced you that:
- It associates a name with the state of an instance of a type
<T>- I say state rather than value because it works better with
Vec<T>, String… - Think about the hash code if necessary
- I say state rather than value because it works better with
- It adds properties
- of mutability
- of ownership
- of borrowing
- of lifetime
- During static analysis, different tools (lifetime checker, borrow checker, etc.) ensure that the properties of the bindings are respected.
I propose that from now on, in the context of Rust, I no longer speak of variables but only of bindings.
Indeed, from my point of view the word “variable” is inherited and more appropriate for classic imperative languages (C, C++, Python…), where a variable is:
- a name
- which references a memory cell
- in which the value can change
If we talk about binding (and we constantly keep in mind binding = name + value + ownership + mutability + borrowing + lifetime) we are better able to ask the right questions or reason about a compiler message. A binding in Rust is a contract of possession and use.
-
I know, integers don’t usually pass through the stack, but it’s just an example. ↩